
6 pasos para crear un proyecto de Machine Learning
Los proyectos de machine learning pueden cubrir muchos temas diferentes, es por ello, que es importarte diseñar un marco que se pueda usar para abordar diferentes problemas.
Digamos que podemos pensarlo a este marco como una guía de trabajo, a la cual, podamos consultar cuando nos encontremos con un problema. Este marco o guía está dividida en pequeños pasos como partes, para llegar a la resolución del problema.
El marco propuesto consiste en una guía de 6 pasos:
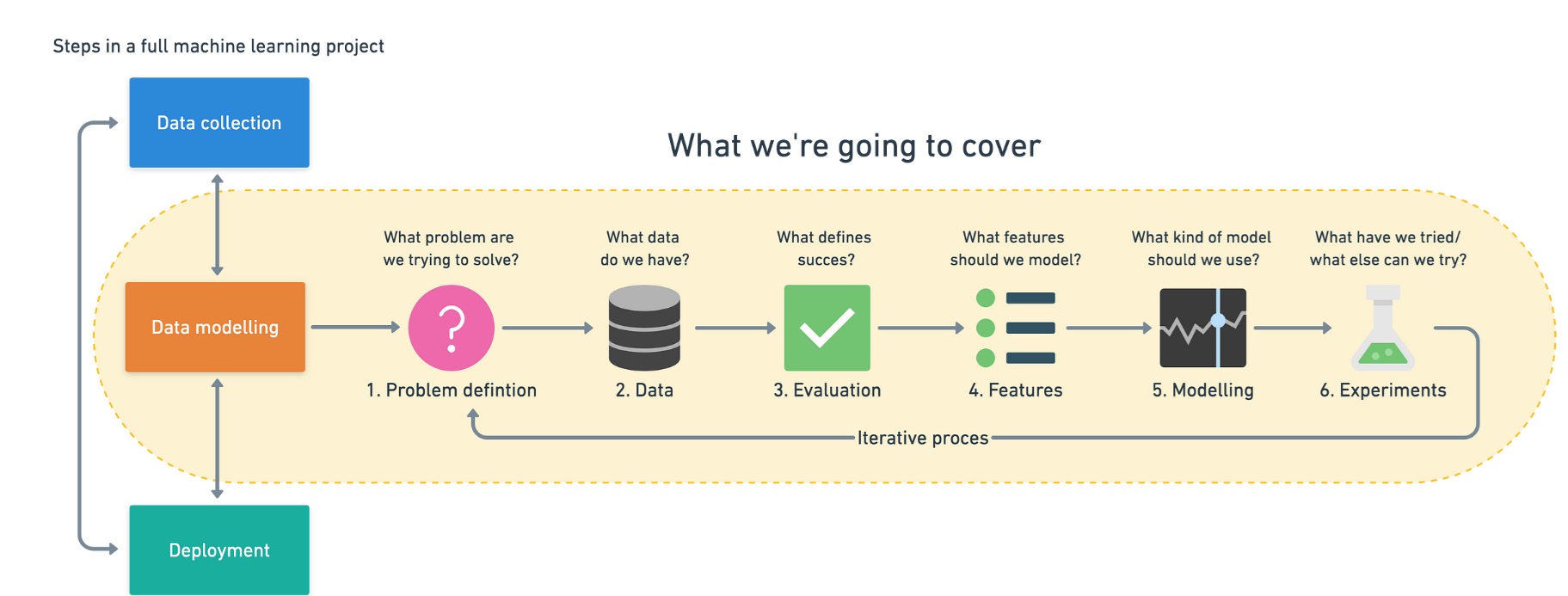
Los proyectos de aprendizaje automático se pueden dividir en tres pasos: recopilación de datos, modelado de datos e implementación. En este artículo nos vamos a centrar en el modelado de datos, que es lo que va a conformar nuestro marco o guía. Estos pasos son el resultado de aplicarlos en varios proyectos de machine learning y en industrias diferentes.
Consta de 6 pasos:
1.- Definición del problema
Es importante definir qué tipo de problema estamos intentando resolver y si se puede expresar como un problema de aprendizaje automático. Es decir, para ayudar a decidir si su empresa podría o no utilizar el aprendizaje automático, el primer paso es hacer coincidir el problema comercial que está intentando resolver con un problema de aprendizaje automático.
Los tipos de aprendizaje automático más utilizados en las empresas son el supervisado, no supervisado y por transferencia. Entonces lo siguiente es definir cuál de estos es el adecuado para resolver mi problema. ¿Es un problema de regresión, de clasificación o de recomendación?

2.-Datos
Los datos son un requisito para cualquier proyecto de aprendizaje automático. La pregunta que tenemos que responder en este paso es: ¿qué tipo de datos tenemos según el problema? Los datos que tengas o necesites recopilar dependerán del problema que quieras resolver.
Si ya tienes datos, es probable que estén en una de dos formas: estructurados o no estructurados. Los datos estructurados como filas y columnas, aquellos que puedes encontrar en una hoja de cálculo Excel, por ejemplo y los no estructurados pueden ser imágenes, audios…Una vez que sepamos que tipo de datos tenemos, podemos comenzar a tomar decisiones sobre cómo usar el aprendizaje automático con ellos.
3.-Evaluación. ¿Que define el éxito?
Hemos definido el problema empresarial en términos de aprendizaje automático, ahora hay que definir lo que significa el éxito para nosotros desde el aprendizaje automático, dado que gran parte del machine learning es experimental.
Podríamos seguir por siempre tratando de mejorar los resultados en busca del modelo perfecto, sin embargo, como somos profesionales sabemos que el modelo perfecto no existe.
En cambio, decimos que para que un proyecto de aprendizaje automático sea factible, necesitamos al menos un modelo con precisión del 95 %. Al principio esta métrica de evaluación no será exacta y cambiará con el tiempo.
¿Pero cómo se determina la precisión de un modelo de ML? Bueno una explicación sencilla seria esta:
La precisión es una forma de medir qué tan bien está funcionando un modelo de machine learning. Básicamente, responde a esta pregunta: «De todas las predicciones que hizo el modelo, ¿cuántas fueron correctas?
Ejemplo:
Imagina que estás jugando a un juego de adivinanzas.
Tu trabajo es adivinar si las cajas en una mesa tienen una manzana adentro o no.
Preparación:
Alguien ya revisó las cajas antes y te dijo cuáles tienen manzanas y cuáles no (esta es la verdad que usaremos para comparar).
Tu modelo:
Tú creaste un robot adivinador que mira las cajas y dice si tienen una manzana o no.
Predicciones:
El robot revisó 10 cajas:
Acertó en 7 cajas: dijo «sí» o «no» correctamente.
Se equivocó en 3 cajas: dijo «sí» cuando era «no» o «no» cuando era «sí».
¿Qué tan bien lo hizo el robot?
La precisión es simplemente la cantidad de veces que el robot acertó dividido por el total de cajas que revisó.
4.- Características: ¿Qué características tienen sus datos y cuáles puede utilizar para construir su modelo?
¿Qué es lo que conocemos de nuestros datos? Pues dentro de diferentes tipos de datos, existen diferentes características.
Por ejemplo, para predecir una enfermedad cardiaca, se puede usar el peso corporal como característica, ya que el peso corporal es un número. Se llama característica numérica.
En cambio, el sexo del paciente es una característica categórica.
Características derivadas: características que creas a partir de los datos. A menudo se las denomina ingeniería de características. La ingeniería de características es la forma en que un experto en la materia toma su conocimiento y lo codifica en los datos.
Un objetivo de los algoritmos de aprendizaje automático es convertir estas características, como el sexo, la presión arterial, dolores en el pecho en patrones para hacer predicciones.
5.- Modelado: ¿Qué modelo debería elegir? ¿Cómo puede mejorarlo? ¿Cómo lo comparo con otros modelos?
La pregunta aquí que debemos hacernos es: ¿qué tipo de modelo de aprendizaje automático deberíamos usar?
No necesitamos empezar de cero, muchos de los algoritmos de ML más útiles, ya están codificados para nosotros, algunos modelos funcionan mejor que otros para abordar cierto problema, por lo cual al principio nuestro objetivo será encontrar el modelo correcto para el tipo de problema correcto.
6.- Experimentación
Todos los pasos que acabamos de ver suceden en un ciclo, puede pasar que, en la definición del problema, nos damos cuenta de que los datos, no se ajustan a él. Luego podemos crear un modelo y descubrir que no funciona tan bien como se describió en la métrica de evaluación.
Entonces construyes otro modelo y descubres que este funciona bastante bien. Pero lo importante a tener en cuenta, que estos pasos son flexibles y no deben seguirse en un orden, sino considerarlos una guía aproximada.
Conclusión:
En esta guía hemos propuesto los pasos fundamentales a seguir en todo proyecto de machine learning, aplicable a cualquier ámbito empresarial.
Deja una respuesta